Guides
Mission and Commitment to Data Sharing
Submission Process
Log in with NetID
The first step to depositing data within the Illinois Data Bank is logging in with your Illinois NetID and Active Directory password. The Illinois Data Bank will check your NetID and confirm that you belong to a group eligible for self-deposit. Illinois faculty, graduate students, and most staff are eligible for self-deposit, but others (including undergraduates) will see a restriction notice after logging in.
✉ Contact the Research Data Service staff if you run into trouble or need to request authorization for self-deposit.
Describe Your Dataset
The information you provide here will be attached to your dataset as metadata associated with your DOI. Providing detailed descriptive information is important because it will be transmitted to search engines such as Google Scholar and other aggregators that look at data. The clearer you can describe your data, the easier it will be for others to find and make use of it!
You can always edit and expand your metadata after publication. Research Data Service staff also regularly review the metadata and add information to increase the visibility of your dataset. Sections to add information about your dataset:
-
Title: provides descriptive title to reflect the dataset. Tip: common used format: Data for [insert article title].

-
Description: allows you to provide brief information about the dataset you are publishing, including information about the data files and their contents. You may choose to repeat a portion of your main documentation file here as well. Tip: information in this section should describe your dataset, not summarize the associated paper.

-
Keywords: enhances dataset searchability. Tip: use semicolon (;) to separate the list of keywords and add any words from the title that would be searchable in the keywords list.

-
Funder: allows you to provide grant or other information about financial support of your dataset.

-
Related Materials: is where you can provide information about scholarly works that use or have contributed to your dataset. Research Data Service staff review this section and create links between these works and your dataset record. This allows publishers and altmetrics tools to make connections to your published data.

Upload Files
You may either drag and drop the files or upload directly from your computer. This is a reliable method for files up to 4 GB. Please refer to the File Grouping guide for additional guidance on datasets with folders or more than 12 files. We recommend limiting to 100 files per dataset or fewer for usability.
Depending on your file size, several Advanced Upload Options options are available. For large or complex datasets, we also support advanced methods such as command‑line upload tools and Globus (which is recommended for files larger than 50 GB). The cURL command line tool can be used for files up to 4 GB. Our API via a sample Python script or a custom script of your own can be supported for files up to 50 GB.
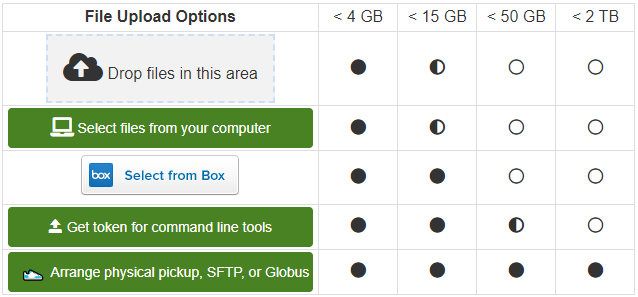
Files larger than 500 GB require special handling, so please see the large file transfer request form for details.
You may save and exit your draft at any time. Let us know if we can help you get your data prepared and documented.
*NOTE: Unlike the metadata, you will not be allowed to edit or change your data files after publication without curator assistance. ✉ Contact the Research Data Service staff if you need assistance during uploading phase.
Upload Using Command Line Tools
Overview
These tools can be used to upload files an existing draft dataset in the Illinois Data Bank.
What do we mean by a draft dataset?
A dataset is in a draft state in the Illinois Data Bank after the deposit agreement has been accepted and before the dataset is published or scheduled for publication. Before uploading a file using any of these options, create or find your draft dataset, and navigate to the edit form for that dataset.
How do I get started?
At the bottom of the Files section of any draft dataset is a matrix of upload options buttons.
Click the Get token for command line tools button to display required elements for use in command line tools.
Notes:
-
Anyone can use a token to upload a file to this dataset, so keep it secure.
-
A distinct token is required for each dataset.
OPTIONS: Python, cURL, or custom script
Download our sample python client databank_api_client_v2.py
Requires recent version of python 2 or 3, works on files up to 2 TB.
Required Modules
pip install tuspypip install requestspip install urllib3[secure]"A version of the following template command, pre-populated with your dataset identifier and token, comes up in response to clicking on the Get token for command line tools button when editing a draft dataset. The only part that would need to change from that example would be the name of your file at the end where that example has myfile.csv and this template has [FILE_TO_UPLOAD].
python databank_api_client_v2.py [DATASET_IDENTIFIER] [TOKEN] [SYSTEM] [FILE_TO_UPLOAD]Arguments:
TOKEN: authentication token, obtained on screen opened by Get Token for Command Line Tools button on edit screen for draft dataset
SYSTEM: optional system indicator (local | development | production), default is production
FILE_TO_UPLOAD: name of your datafile to be uploaded
Options: -h --help
This python script and accompanying documentation can be found on GitHub
at https://github.com/medusa-project/databank-client.
For more help, Contact Us.
Institute for Genomic Biology
The IllinoisDataBank module on biocluster2, available to any user of the system, ensures a python environment with the modules needed to upload files using our custom Python script, as further described in the above section.
module load IllinoisDataBankAWS
The default Linux system in AWS already has Python along with the 'requests' and 'urllib3' modules installed, so only the 'docopts' module would need to be installed, as in the instructions in the section above.
Virtual Hosting Group at Technology Services
Since the OS installation and component parts are handled by the tenant, tenant owners have full administrative rights to follow the instructions in the section above.
For more help, Contact Us.
Requires cURL, works on files up to 4 GB.
A version of the following example command, pre-populated with your dataset identifier and token, comes up in response to clicking on the Get token for command line tools button when editing a draft dataset. The only part that would need to change from that example is the name of your file in the "binary = @my_datafile.csv" section. The at symbol (@) is required just before the file name.
curl -F "binary=@my_datafile.csv" -H "Authorization: Token token=[TOKEN]" -H "Transfer-Encoding: chunked" -X POST https://databank.illinois.edu/api/dataset/[DATASET_IDENTIFIER]/datafile -o output.txtThe basic endpoint URL pattern is https://databank.illinois.edu/api/dataset/[DATASET_IDENTIFIER]/datafile
The request method is POST.
The authorization token must be sent in a header.
A header setting the Transfer-Encoding to chunked is recommended.
The file must be sent in a form in an element named binary. In cURL, that can be done with the -F option and an element like "binary=@my_datafile.csv".
The -o option must be used to send response output to a file to see the progress meter.
Even after the cURL progress meter reaches 100%, additional processing is done, which may take as long as it took to reach 100%.
After upload is complete, refresh the dataset page to see the new datafile listing.
For more help, Contact Us.
Size constraints depend on implementation details.
Simple Protocol
The simple one-call protocol supports files
The curl example above uses the simple protocol.
The basic endpoint URL pattern is https://databank.illinois.edu/api/dataset/[DATASET_IDENTIFIER]/datafile
The request method is POST.
The authorization token must be sent in a header.
A header setting the Transfer-Encoding to chunked is recommended.
The file must be sent in a form in an element named binary.
After upload is complete, refresh the dataset page to see the new datafile listing.
Complex Protocol
The complex protocol, used by the sample python client above, requires a tus protocal client, but supports files up to 2TB in size, to an existing draft dataset with an authentication token and dataset key as described above.
An example of using the complex protocol in a python script can be found on GitHub at https://github.com/medusa-project/databank-client.
For more help, Contact Us.
Upload Using Globus
Globus is a nonprofit platform created by the University of Chicago and Argonne National Laboratory that enables the transfer of digital files between established endpoints, one of which can be your work or personal computer. Globus also offers additional services related to sharing data with other researchers or parties directly.
The datasets in Illinois Data Bank's repository hold files of varying sizes. While files can be downloaded directly from datasets through a browser, Globus can offer a faster alternative that can be especially noticeable on datasets larger than a few Gigabytes.
To set up your systems to use Globus to transfer files to your computer, refer to the getting started guide from Globus for detailed guidance on setting up and account and installing Globus Connect Personal.
Once you configure and select an endpoint to send the files to (on your personal computer or other system) you can click on the "Open in Globus File Manager" button on a dataset download page.
Publish Your Dataset
After describing your dataset and uploading files, review your submission to confirm it is complete. If you need more time, you can save your progress and return later.
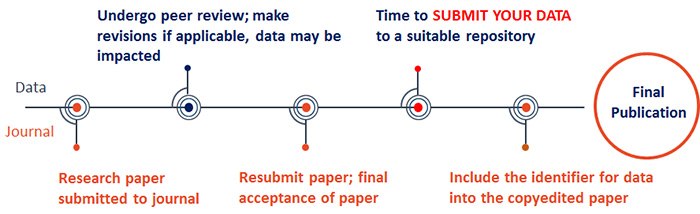
Before your dataset can be published, it must be submitted for Pre-Publication Review. Once you submit your dataset for review, your reserved DOI will display on your confirmation screen and in your dataset record. This DOI is permanent and should be used to cite your dataset in any associated publications. Your reserved DOI will activate once the review is completed (typically 2-5 business days) and your dataset is published.
During the review, a curator will contact you to discuss suggestions for improvements and a publication timeline that works for you. If your dataset is associated with a paper, we highly recommend publishing your data after the paper is officially accepted since paper reviewers may request revisions to the dataset.
To share your dataset before it is published, generate a private sharing link using the “Generate private sharing link” button on your dataset page. Share this link with reviewers or co-authors if they need to view your dataset while it is under review.
Once the review is complete and you approve the final version, the curator will work with you to confirm an appropriate publication date and will publish the dataset on your behalf.
*NOTE: for embargoed dataset, the dataset must be published in order for it to be available on the released date.Curation Process
What is data curation?
Data curation is a set of activities that enables data discovery and retrieval, maintains data quality, adds value, and provides for re-use over time through activities including authentication, archiving, metadata creation, digital preservation, and transformation. The person who performs this work is a data curator, and these professionals collaborate with researchers to share data ethically and in ways that are Findable, Accessible, Interoperable and Reusable by aligning with the
How are datasets curated in the Illinois Data Bank?
Research Data Service staff monitor and curate all datasets submitted to the
Illinois Data Bank curation workflow aims to follow the DCN's established
Check files/code and read documentation (risk mitigation, file inventory, appraisal/selection)
Understand the data (or try to), if not… (run files/code, QA/QC issues, readmes)
Request missing information or changes (tracking provenance of any changes and why)
Augment metadata for findability (DOIs, metadata standards, discoverability)
Transform file formats for reuse (through suggested actions for data preservation, conversion tools, data visualization)
Evaluate for FAIRness (transparent usage licenses, responsibility standards, metrics for tracking use)
Document all curation activities throughout the process
If you deposit a dataset into the Illinois Data Bank, what can you expect?
An automated email confirming your pre-publication review request
A personal email from Research Data Service staff relating to suggested changes to metadata and/or data file(s)
All suggestions from curators are optional, and depositors have the right to accept or reject those suggestions
Who can help with data curation?
Delay Publication (Optional)
The primary purpose of the Illinois Data Bank is to provide University of Illinois researchers a space to make their research data openly available immediately to anyone in the world. We do recognize that there are sometimes cases where, due to publisher or other requirements, researchers may need to deposit their dataset but make it temporarily unavailable for download. To meet this need, we provide the following two options for temporarily delaying publication of datasets in the Illinois Data Bank:
File Only Publication Delay |
Metadata and File Publication Delay |
|---|---|
You receive an active DOI.You will receive a DOI, and the link will forward to the Illinois Data Bank page for your dataset.
|
Your DOI is saved, but the link will fail.You will receive a DOI link to place in your publication, but the link will fail until the release date you selected.
|
Your dataset record is discoverable.Information for your dataset in the Illinois Data Bank will be publicly visible through several search engines and other sources.
|
Your dataset record is not discoverable.Your dataset will be stored in the Illinois Data Bank, but is not discoverable or visible until the release date you selected.
|
Dataset files cannot be accessed or seen.Although the record for your dataset is publicly visible, your data files will not be made available until the release date you selected.
|
Dataset files cannot be accessed or seen.The record for your dataset is not visible, nor are your data files available until the release date you selected.
|
Not sure if you should delay publication of your data, what your release date should be, or have any other questions?
Good Data Practices
File Formats
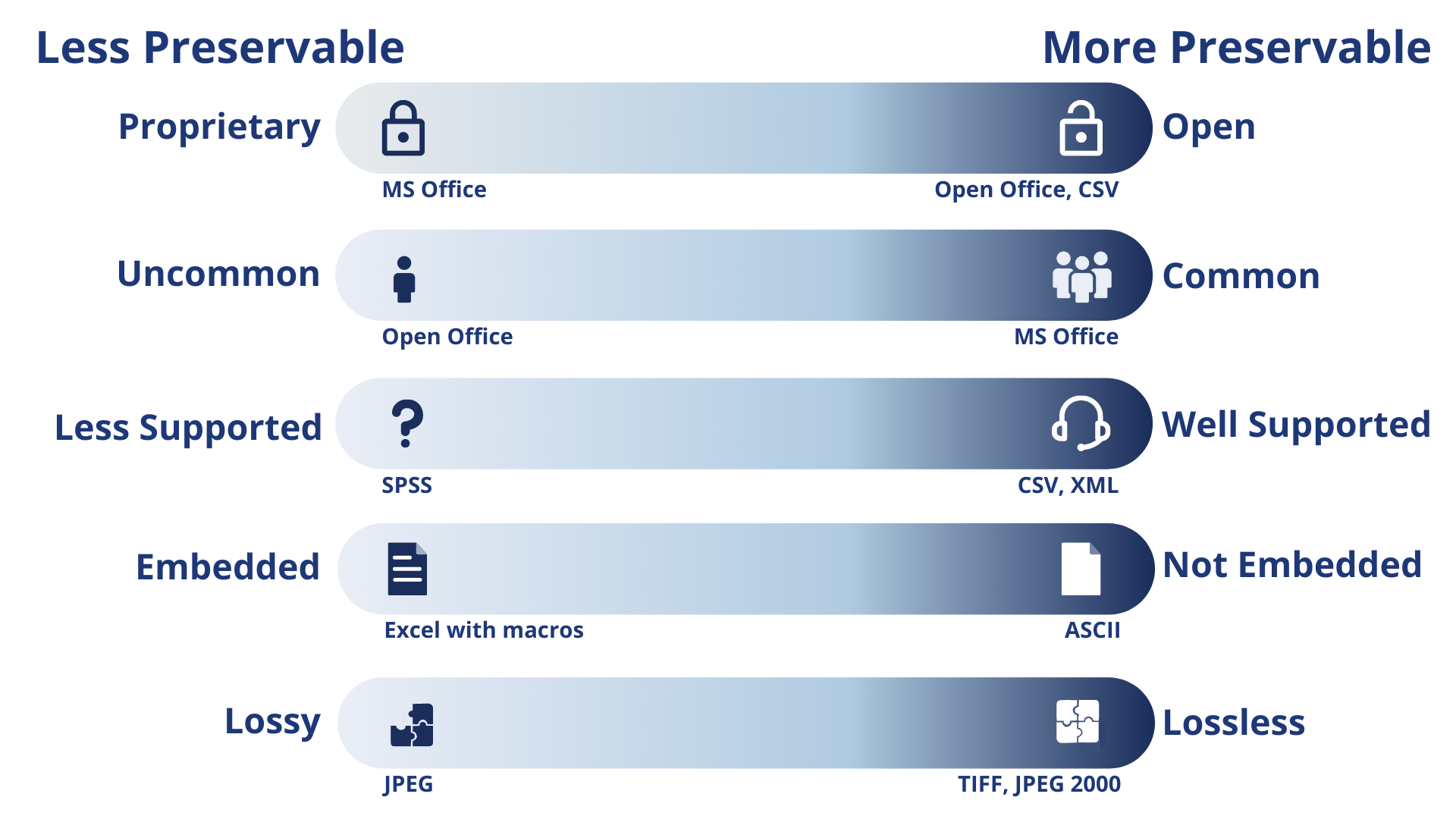
The file formats of deposited data and associated documentation effect the access, use, and preservation of content. Proprietary file formats reduce the ability for other researchers to use your data. Some scholars work at institutions that cannot afford a certain expensive software, or the proprietary file format may not be compatible with the software they use. In addition, the preservation of data greatly depends on it's file format.
We suggest that all possible data deposits be in an open, non-proprietary file format. This may require conversion from a proprietary file format used during research to an open file format for sharing purposes. Check for errors or omissions after conversion to ensure data integrity. If conversion to an open file format is not possible, please provide information about the file format in the associated dataset documentation. Documentation should include: name and version of software used, year and/or company who made the software instrument, information about the required operating systems, and other information needed to be able to use the file.
**Further Reading:**
eCommons. Recommended File Formats. Cornell University Library.
Research Data Service. (Apr. 2021) File format considerations for data sharing. Data Nudge.
Research Data Service. (Jan. 2018) Your File Formats Matter. Data Nudge.
United States Geological Survey. File Formats.
Van den Eynden, Veerle, Corti, Louise, Woollard, Matthew, Bishop, Libby, and Laurence Horton. (2011). Managing and Sharing Data: Best Practice for Researchers. UK Data Archive.
File Naming
File names need to indicate to the user what content is inside the file. File names should be consistent, unique, easy, and meaningful. Without clear file names, researchers (yourself included) will be confused as to the purpose and relationship between files. Using underscores or hyphens instead of spaces between words also reduces interoperability issues between operating systems. All deposited files and directories should follow a consistent file naming convention. The following table lists file naming best practices and examples.
File naming best practice | Examples |
|---|---|
| Use YYYY-MM-DD format | project01_2019-01-01 |
| Use combination of letters, numbers, underscores, and hyphens | project01_raw-data.json |
| Use standard file extensions to indicate file type | myproject.txt |
| Use leading zeroes for version | name001.csv name010.csv name101.csv |
| Keep file name short | not_too_long.xml |
| Use alphanumericals | data_champaign_il_2019-01-01.csv |
| Use underscore between words | data_location_time.csv |
| Use lowercase (some systems are case sensitive) | all_lowercase_would-be-safer.tiff |
File Grouping
Uploading lots and lots of files in a single dataset without directory organization can make data difficult to curate, upload/download, understand, and reuse. A long list of files may overwhelm potential users and can also cause technical issues such as slow or failed page loading. Grouping files together may make your dataset easier to deposit and use.
In addition, you will need to zip any folders or subdirectories before uploading them. The Illinois Data Bank lets you upload files but not entire folders. Zipping your files ensures your existing folder structure is kept during the deposit process.
File grouping strategies to consider:
- Organize your files into logical groups (i.e. by time, location, project - whatever would be most helpful to someone reusing your data)
- Add a note to your data documentation about the groupings you chose and why
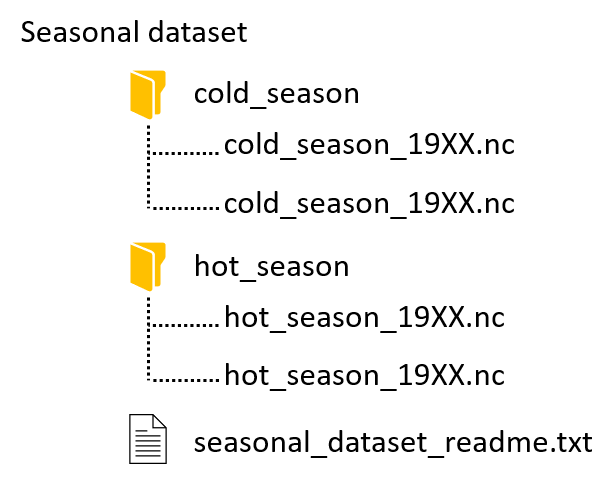
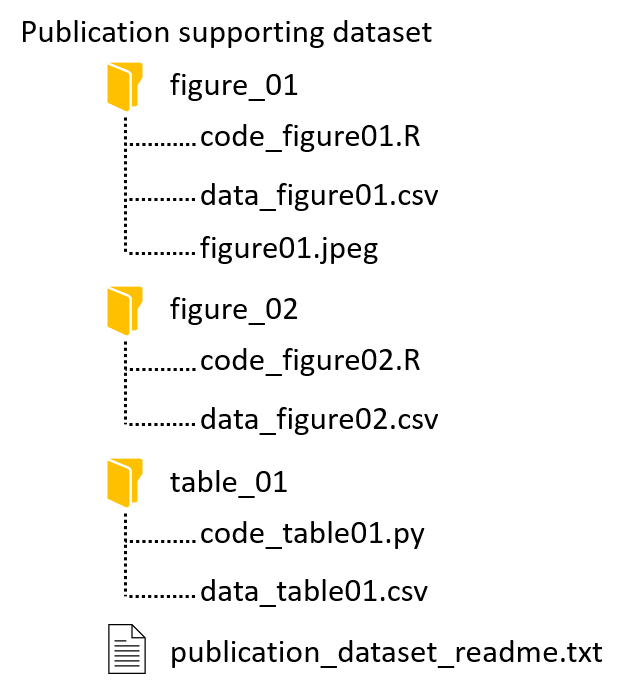
| Example 1: Temporal organization by seasons and years | Example 2: Publication supporting organization by figures, tables | Example 3: Topical organization by species name and treatment types |
|---|---|---|
 |  | 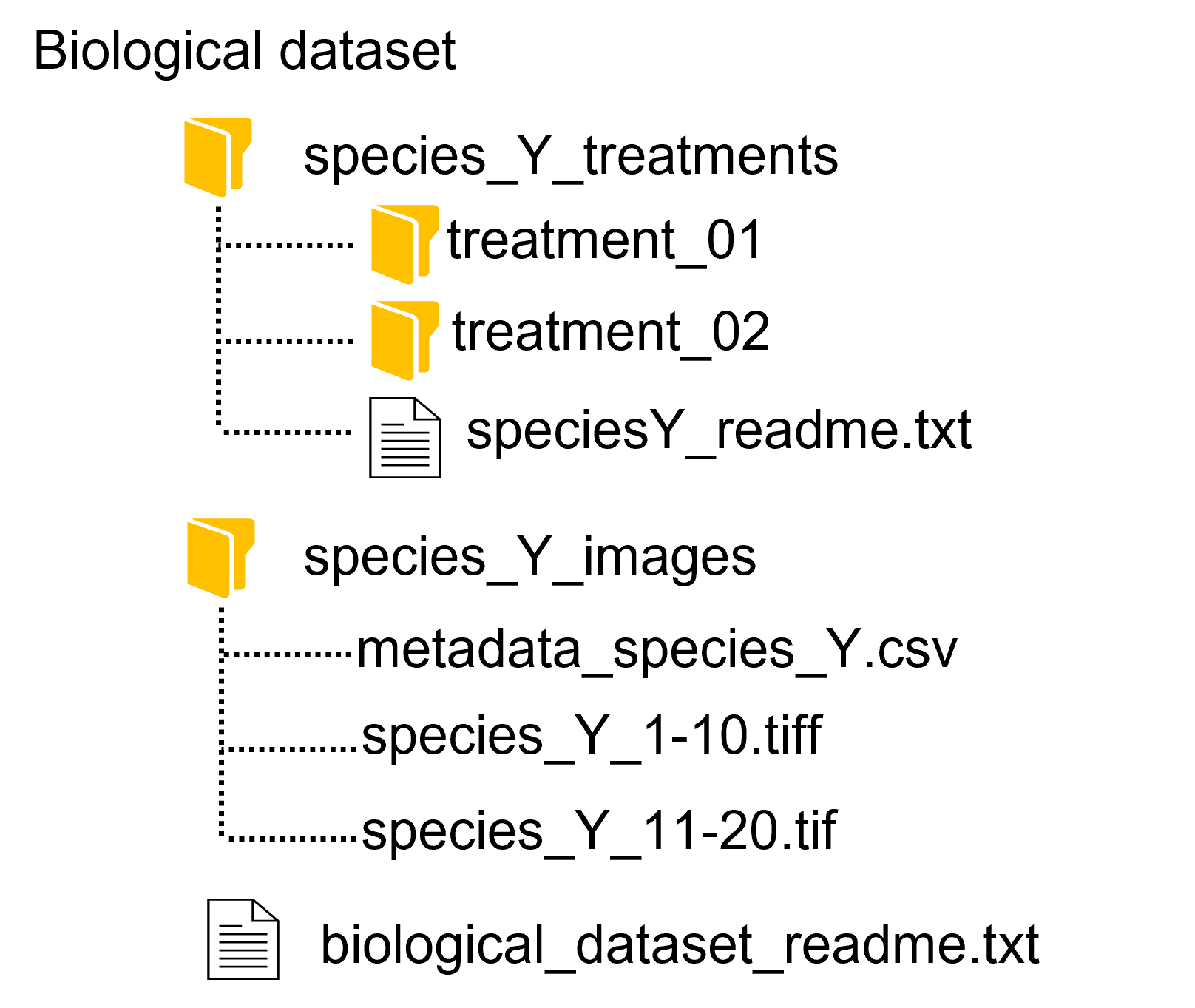 |
Other categories to consider include:
- topical (e.g. by species, treatment, etc)
- temporal (e.g. by year, month, season, etc)
- spatial (e.g. by county, state, country, etc)
- file type (e.g. by spreadsheet, text, code, etc)
- publication supporting (e.g. by figure, table, etc)
- workflow (e.g. by inputs, outputs, etc)
We're happy to consult with you on grouping strategies for your dataset,
Willson, James; Roddur, Mrinmoy Saha; Baqiao, Liu; Zaharias, Paul; Warnow, Tandy (2021): Data from: "Inferring Species Trees from Gene-Family with Duplication and Loss using Multi-Copy Gene-Family Tree Decomposition". University of Illinois at Urbana-Champaign.
Schroeder, Nathan (2020): Burton Endo electron micrograph library. University of Illinois at Urbana-Champaign.
Donovan, Brian; Work, Dan (2016): New York City Taxi Trip Data (2010-2013). University of Illinois at Urbana-Champaign.
Zip Files
It is a good data practice to zip files in order to share with others, as the size of a dataset may be too large for some computers. Zipping files reduces the size while also keeping all the associated files in one directory. In order to keep your file and directory organization during submission to the Illinois Data Bank, you will need to zip your files together. Try to keep each group under 10 GB before you zip it so it's easier to download. Please note that while we use the term zip in this section, you can often hear it referred to as compression. Use a resource you are familiar with to zip your files, such as
For more information on the most common forms compressed file formats refer to:
Research Data Service. (Aug. 2018) Common Zipped File Format Used in Research. Data Nudge.
Data Documentation
We encourage dataset authors to develop documentation that will make it possible for you and others to understand and interpret your dataset in the future. Through the process of depositing in the Illinois Data Bank, you will provide high-level documentation for your dataset, such as title, creator, etc. It is likely that there are many additional details about your dataset that cannot easily be included as a part of this basic description. To provide customized, detailed information about your dataset, we recommend that you include a documentation file as a part of your dataset deposit.
Dataset documentation is critical for future users of the data to understand it and to ensure its proper interpretation. Without documentation, the quality and provenance of the data is questionable. A related research publication does not provide enough information about the data itself, such as file organization and units of measurement, though related scholarship should be connected to the dataset during the deposit process (if available at the time).
For more information about how to develop documentation files, please refer to these excellent resources:
Readme files: Simple text file that accounts for all files and folders in a dataset
- Cornell University. 'Guide to writing 'readme' style metadata.'
Codebooks: Contains study-level information and descriptions of each variable/data item
- Agency for Healthcare Research and Quality. 'What is a codebook?'
Data Dictionaries: Provides a detailed description for each element or variable in your dataset and data model.
- University of Wisconsin Data Services. 'Data Management: Data Dictionaries.'
Data Licenses
This section provides basic information about intellectual property rights and how they apply to sharing research data. The material in this section is for informational purposes only and not for the purpose of providing legal advice.
CC0CC0 1.0 Universal public domain dedication | CC BYCreative Commons Attribution 4.0 International license | Other LicenseA license.txt file must be uploaded as part of dataset. |
|---|---|---|
Derivative works are allowedMost open license with no restriction. | Attribution a legal requirementPartially open license with restriction. | Other CC licenses may create reuse difficultiesCC NC, CC SA, and CC ND impose restrictions that may create incompatibilities and licensing difficulties for the reuse of research data.More restrictions depending on which license is chosen. |
Request for attributionAttribution is not required but creators can ask for it by including citation requests or other attribution information in the documentation of the dataset. | May create reuse difficultiesKnown as " | Custom licensing considerationsWriting a custom license requires legal expertise and non-standard licenses complicate reuse. |
What is copyright?
Copyright is a property right in an original work fixed in any tangible medium of expression giving the holder the exclusive right to reproduce, adapt, distribute, perform, and display the work.
What is a license?
A license is a legal instrument for a rights holder to permit a second party to do things that would otherwise infringe on the rights held.
How does copyright law apply to research data?
Datasets are complex objects, and understanding how copyright law applies to datasets is similarly complex. Copyright protection does not extend to "facts", and so what researchers often view as their "raw" data are in the public domain. Therefore, dataset authors typically cannot claim copyright for raw data. Copyright can apply to aspects of a dataset for which an author made creative or editorial decisions about how the raw data is expressed. For example, the manner in which data are selected and arranged may be copyrightable. Creators may be able to claim copyright over any visualizations, figures, charts, graphs, and other forms of "processing" of research data as well.
When researchers publish datasets in the Illinois Data Bank the license they assign to their dataset applies only to the copyrightable content of the submission. The raw data and any other part of the dataset submission that is a part of the public domain cannot be licensed.
Why license research data?
-
To mitigate legal uncertainty for downstream users.
-
To control the way you participate in data sharing.
For more information
Ball, Alex. 2014. 'How To License Research Data'. Digital Curation Centre.
Carroll, Michael W. 2015. 'Sharing Research Data And Intellectual Property Law: A Primer'. PLOS Biology 13 (8): e1002235.
RDA-CODATA Legal Interoperability Interest Group. 'Legal Interoperability of Research Data: Principles and Implementation Guidelines.'
Urbana Campus of the University of Illinois. 'Illinois Copyright Policy.'
University of Illinois. 'The General Rules Concerning University Organization and Procedure,' in particular Articles II and III.
1 Black's Law Dictionary 10th Edition, 2009.
2 Ball, Alex. 2014. 'How To License Research Data'. Digital Curation Centre.
Frequently Asked Questions
When do I use the Illinois Data Bank vs. IDEALS?
While
The Illinois Data Bank defines data in our terminologies as “Factual material commonly accepted in a given research community as necessary to validate or extend research findings. Data may be qualitative, in the form of literature, interviews, observations, etc., or quantitative, in the form of numerical, spatial, measurements, etc.” If the content’s purpose is to discuss research, a project, or an act of scholarship, it should be deposited into IDEALS. If the content was collected and/or created during the research process and is necessary for the reproduction of research, then it should be deposited into the Illinois Data Bank.
Examples of Illinois Data Bank content:
- Data output (of various types) from a technical instrument
- Cleaned data collected from field studies and field notebooks
- Cleaned, deidentified, non-PII interview data
- Research data documentation
- Code necessary to access and use a research dataset
Examples of IDEALS content:
- Thesis and dissertations
- Presentation slides
- Publication pre-prints
- Electronic theses and dissertations
- Audio or video recording of a presentation
Why to use/deposit to the Illinois Data Bank?
Use data in the Illinois Data Bank because it:
- Provides freely accessible and openly licensed research data (refer to individual datasets for specific licensing information)
- Supplies a DOI for easy and persistent sharing
- Is curated by data experts and subject specialists to improve usability and preservation efforts
- Reduces the unintentional duplication of research efforts
- Allows you to build off of existing data created by UIUC researchers
Deposit data into the Illinois Data Bank so you can:
- Meet research data sharing requirements as outlined by funding agency and/or publisher
- Include your dataset metrics as evidence of scholarly impact
- Show professional and ethical commitment to improving research reproducibility and reducing barriers to research access
- Add dataset DOI to related research publications for increased visibility
- Choose between pre- and post-deposit for dataset curation to ensure sustainability and future researcher understanding
- Improve access and findability of your data through Illinois Data Bank search engine indexing
Some publishers offer the option of contributing data as "supplemental materials" in the form of a pdf. The Illinois Data Bank can provide a more flexible alternative, as detailed below:
Criteria | Supplemental Material | Illinois Data Bank |
|---|---|---|
| Size limitations on files | Often lower than 100 MB | 2 Terabytes |
| Format limitations on files | Restrictions and requirements are possible. Often PDF only. | Any format is accepted |
| Digital Object Identifier (DOI) | Unlikely to be available | Automatically provided |
| Metadata available, exportable, and searchable | Unlikely to be available | Automatically provided |
| Access restriction / findability | Can be hidden by paywalls or publisher-chosen access controls. | Data will be freely available (after release from any embargoes you choose to assign). |
| Download statistics | Unlikely to be available | Automatically provided |
| Storage infrastructure | Stability and suitability for long term storage is usually not be guaranteed | Stable preservation environment that complies with many funder and publisher requirements |
| Cost to publish | Sometimes fee-based | No cost for University of Illinois researchers |
| Guaranteed availability | Unlikely to be guaranteed for multiple years or regularly reviewed | Every dataset is guaranteed to be available for a minimum of 5 years, with longer storage likely. Regular review and curation will ensure continued availability and preservation best practices as time passes. |
| Connections to additional papers that uses the data and other materials | Sometimes available | We link your dataset to articles, code, theses, other data sources, etc. |
| Standard or custom licensing statements | Unlikely to be available | CC0 and CC BY are standard offerings; you can also upload a customized license statement. |
How does Illinois Data Bank help you meet the data sharing requirements?
The Illinois Data Bank is certified as a trustworthy repository and meet data sharing requirements for federally funded research. It aligns with the desirable characteristics for repositories agreed to by Federal agencies1 and meets the CoreTrustSeal organization's 2023-2025 requirements2 (see the table below).
The Office of Science and Technology Policy (OSTP) provides a guidance document outlining desirable characteristics for data repositories1. This guidance serves as a tool for the research community - including investigators, program officers, data managers, librarians, and others - to identify data repositories that comply with Federal data sharing policies. In 2024, the Illinois Data Bank achieved certification as a trustworthy data repository based on the CoreTrustSeal's 2023-2025 Core Trustworthy Data Repositories Requirements3. CoreTrustSeal is an international, community based, non-governmental, and non-profit organization promoting sustainable and trustworthy data infrastructures.
Desirable Characteristics of Repositories | Illinois Data Bank |
|---|---|
| Free and Easy Access |
|
| Clear Use Guidance |
|
| Risk Management |
|
| Retention Policy |
|
| Long-term Organizational Sustainability |
|
| Unique Persistent Identifiers |
|
| Metadata |
|
| Curation and Quality Assurance |
|
| Broad and Measured Reuse |
|
| Common Format |
|
| Provenance |
|
| Authentication |
|
| Long-term Technical Sustainability |
|
References
- 1 The National Science and Technology Council, Desirable Characteristics of Data Repositories for Federally Funded Research, 2022, DOI:https://doi.org/10.5479/10088/113528.
- 2 CoreTrustSeal Standards and Certification Board. (2022). CoreTrustSeal Requirements 2023-2025 (V01.00). Zenodo. DOI:https://doi.org/10.5281/zenodo.7051012
- 3 Illinois Data Bank. (2024). "2027-09-19 - Illinois Data Bank - CoreTrustSeal Requirements 2023-2025". DataverseNL. DOI:https://doi.org/10.34894/TKWRBT.
When do I publish a dataset in the Illinois Data Bank?
We suggest publishing a dataset with the Illinois Data Bank after a journal article or other work of scholarship has reached final acceptance with a publisher. When a dataset is published with the Illinois Data Bank, the submitter can then include the dataset DOI in the journal article for easy linking.
Please note, we accept data from research projects that will not be published and/or published in traditional ways. As long as the data meets the
What is a DOI?
A
Access: DOIs have associated redirect links, usually a page pointing to where the resource can be accessed. Any changes to where the resource is located on the web can be sent to the DOI resolution database and the DOI will automatically begin forwarding to that new page. This means that you are free to use this DOI link within static publications without fear that a resource migration or other URL change may break the link.
Discovery: DataCite, the resolution service that the Illinois Data Bank uses for minting DOIs, also accepts descriptive information about the registered data objects. This metadata is indexed by several search engines and promotes the discovery of the resources for future users.
Reserve DOI vs. Active DOI: The two types of DOI we use. If you choose to have your data curated before publishing, a reserve DOI will be attached. This reserves the datasets unique DOI, remains the same throughout, but it is not activated yet. The reserved DOI can be included in your upcoming publication. Once the dataset is published, the DOI becomes resolved (activated).
Publishing your dataset within the Illinois Data Bank grants you a DOI for your dataset so you can benefit from a stable URL, increased visibility, and more formalized citation practices. Research Data Service staff members review and edit your descriptive metadata to ensure accuracy and maximize visibility. Curators also add formal links between associated publications so that aggregation and altmetrics services can recognize and include datasets within their reports.
There are two types of DOI's we use: reserve DOI and active DOI. If you choose to do have your data curated before publishing, a reserve DOI will be attached. This reserves the datasets unique DOI, but it is not activated yet for sharing. Once the dataset is published, the DOI becomes actived and is ready for sharing.
Questions or concerns about how DOIs work?
What is metadata?
Metadata is often described as “data about data.” While this is a shallow definition, it works in showing that metadata describes the ‘aboutness’ of data. In the context of the Illinois Data Bank, metadata is provided during the deposit process. The submission metadata includes:
- Dataset Title
- License
- Author(s) name(s)
- Author ORCID ID (if applicable)
- Dataset Description
- Keywords
- Publication Delay & Release Date (if applicable)
- Funder
- Related Resources (articles, presentations, code, etc.)
Full documentation, including current and previous versions, of the metadata that the Illinois Data Bank stores and transmits can be found here:
Metadata describing the datasets housed within the Illinois Data Bank are published in a variety of ways. Individual metadata records may be directly accessed via our internal API. Appending “.json” to a record’s internal URL will provide the Illinois Data Bank’s original metadata. Using “.xml” will provide the version transmitted to DataCite. An index of all available dataset records can be found at https://databank.illinois.edu/datasets.json. External entities are welcome to harvest our metadata records using at least a 2 second access delay. The DataCite API (
What is private sharing link?
How to write a data availability statement
Data availability statements are short, simple explanations of how a dataset referenced in a publication is available to others. When producing a statement for a dataset deposited in the Illinois Data Bank, reference the following:
"The dataset supporting these findings is openly available in the Illinois Data Bank at [DOI received]."What metrics does the Illinois Data Bank collect?
Download metrics
The Illinois Data Bank tracks download counts for datasets. To mitigate possible over- or under-estimation of download counts, a dataset's download counter will increment up by one when one or more any associated files are downloaded or viewed. However, only one download instance will be counted per IP address per calendar day. This means that a single computer downloading a dataset's files multiple times in the same day will only be counted once. IP addresses of downloaders are only used for this purpose and are deleted regularly in compliance with our
Other metrics
Research Data Service team members also collect data on DOI access, individual file downloads, and other citation information about deposits held within the Illinois Data Bank. This information can be found at our
Can I change, update, or add files?
You can add and remove files in draft datasets. A draft dataset does not have a DOI, because it not been published or scheduled for publication.
What do you do if you realize you need to correct an error in a dataset you've already published or scheduled for publication (embargoed)? Or what if you have created a helpful documentation file that you want to add to make it easier for others to understand your dataset? Even though the Illinois Data Bank is designed for publication-ready data, we are available to discuss any situation you may be in where you would like to create a new version of your dataset. Please
If you expect that your dataset might evolve over time (for example, additional data will be added each year), consider setting, defining, and documenting a "release" cycle. For example, if you plan to deposit rainfall data, appropriate release cycles could include a calendar-based season or annual release, which should be clearly indicated in any documentation files that you deposit along with your data files. To determine the granularity of the release cycle you can consider what span of data is most likely to be needed for reuse, how quickly you'd like to make the data public, and how often you can commit to collect, prepare, and document datasets for deposit. Consider requesting a consultation with
How do I download large files using Globus?
The datasets in Illinois Data Bank's repository hold files of varying sizes. While files can be downloaded directly from datasets through a browser, Globus can offer a faster alternative that can be especially noticeable on datasets larger than a few gigabytes.
To set up your systems to use Globus to transfer files to your computer, refer to the
Once you configure and select an endpoint to send the files to (on your personal computer or other system) you can click on the "Open in Globus File Manager" button on a dataset download page.
Definitions of Terms in the Illinois Data Bank
The following are simplified definitions of terms as they are used in Illinois Data Bank policies. Sources are provided where possible; please note that many definitions have been adjusted to reflect the specific context of the Illinois Data Bank.
Creator(s)1
synonym: Author(s)
An individual or group of individuals who make, conceive, reduce to practice, author, or otherwise make a substantive intellectual contribution to the creation of intellectual property (e.g., Datasets).
`Data
Factual material commonly accepted in a given research community as necessary to validate or extend research findings. Data may be qualitative, in the form of literature, interviews, observations, etc., or quantitative, in the form of numerical, spatial, measurements, etc.
Data File
File of Data that enables ready inspection and/or reuse of the Data in visualization tools, analysis software, or analysis scripts.
Dataset2
An intentional collection of Data Files and/or Metadata Files together with the associated Descriptive Metadata.
Note: A Dataset may be as simple as a single Data File and/or Metadata File and the associated Descriptive Metadata. A Dataset could also be a package of any combination of raw, semi-processed, or aggregate Data Files, relevant processing and analysis scripts, and Metadata Files such as a readme file.
Dataset Publishing
The process of making a Dataset publicly available, discoverable, and citable independent of other research publications such as a journal article.
Deaccessioning3
The process by which the Illinois Data Bank removes Data Files and/or Metadata Files from its holdings after the initial commitment period ends if recommended after conducting a Preservation Review.
Note: See theIllinois Data Bank Preservation Review, Revision, Retention, Deaccession, and Withdrawal ProcedureandPreservation Review Guidelinesfor more details about reviewing, revising, retaining, deaccessioning, and withdrawing in the Illinois Data Bank.
Depositor
The person depositing a Dataset into the Illinois Data Bank where the Depositor is a Creator (e.g., has made a substantive intellectual contribution to the creation) of the deposited Dataset or is authorized by such a Creator to act on his/her behalf. At least one of the Creators of such a Dataset must be affiliated with the Urbana-Champaign campus of the University of Illinois before a Creator or someone acting on behalf of a Creator can deposit into the Illinois Data Bank.
Descriptive Metadata
The information about the Dataset being deposited in the Illinois Data Bank, such as Dataset Creator(s), title, funder, etc.
Note: Descriptive Metadata is initially provided by the Depositor during the submission process. Modifications to the Descriptive Metadata can be made after a Dataset is published by the Depositor and/or the Research Data Service staff.
Digital Object Identifier4
abbreviation: DOI
A Digital Object Identifier (DOI) is a unique alphanumeric string assigned by a registration agency (the International DOI Foundation) to identify content and provide a persistent link to its location on the Internet.
Digital Preservation5
Policies, strategies, and actions to allow access to digital content over time regardless of the challenges of media failure and technological change. The goal of digital preservation is the accurate rendering of content over time.
Disposition6
Retention, transfer, or discard of Data Files, Metadata Files, and/or Descriptive Metadata as determined through Preservation Review.
Note: See theIllinois Data Bank Preservation Review, Revision, Retention, Deaccession, and Withdrawal Procedurefor more details about reviewing, revising, retaining, deaccessioning, and withdrawing in the Illinois Data Bank.
Long-Term Contact Person7
synonyms: Corresponding Author, Corresponding Creator
A person who serves as the primary contact and information provider for third parties wishing to find out more about a specific Dataset.
Note: This person generally carries ultimate responsibility for the validity of the Dataset and is most often a faculty member and/or Principal Investigator ("PI") of the project under which the Dataset originated.
Metadata File
File that provides information about a Data File(s) pertinent to the understanding, inspecting and/or reusing of the Data File(s), including descriptive information, documentation, technical specifications, readme files, provenance, and rights information.
Owner
The individual, organization, or other entity that owns the intellectual property rights to the Dataset.
Note: Nothing in these Illinois Data Bank Policies shall be considered as enlarging or reducing the ownership rights of the Creators of the Datasets.
See the University's General Rules, in particular Article III, Sections 5, 4, 2(a) and 2(d) regarding ownership.8
Preservation Review
Assessment of the long-term viability of Datasets published in the Illinois Data Bank that may result in retaining, escalating preservation activities for, transferring, or discarding the Dataset.
Provenance9
Information regarding the origins, custody, and ownership of a Dataset.
Publication Delay Period10
synonym: Embargo Period
The period of time during which public access to all or part of a Dataset is not yet allowed.
Note: The Illinois Data Bank supports publication delay periods for just the Data Files and/or Metadata Files only or for the entire Dataset. The items under publication delay are released to the public on a date specified by the Depositor.
Steward11
The individual, organization, or other entity that is financially and functionally responsible for the organization, Digital Preservation, transfer, and Disposition of a Dataset.
Note: The Illinois Data Bank assumes stewardship responsibility for all Datasets deposited into the Illinois Data Bank.
Withdrawal
The process by which the Illinois Data Bank removes public access to all or part of a Dataset from its holdings for a compelling reason before the initial commitment period ends.
Note: See theIllinois Data Bank Preservation Review, Revision, Retention, Deaccession, and Withdrawal Procedurefor more details about reviewing, revising, retaining, deaccessioning, and withdrawing in the Illinois Data Bank.
References
1University of Illinois. 'The General Rules Concerning University Organization and Procedure,' Article III Section 2(c).http://www.bot.uillinois.edu/general-rules
2Dataverse Project. 'Dataset + File Management.'http://guides.dataverse.org/en/latest/user/dataset-management.html
3Society of American Archivists.A Glossary of Archival and Records Terminology.http://www2.archivists.org/glossary/terms/d/deaccessioning
4American Psychological Association. 'What is a digital object identifier, or DOI?'http://www.apastyle.org/learn/faqs/what-is-doi.aspx
5Association for Library Collections & Technical Services. 'Definitions of Digital Preservation.'http://www.ala.org/alcts/resources/preserv/defdigpres0408
6Society of American Archivists.A Glossary of Archival and Records Terminology.http://www2.archivists.org/glossary/terms/d/disposition
7SCoRO, the Scholarly Contributions and Roles Ontology. 'contact person.'http://purl.org/spar/scoro/contact-person
8University of Illinois. 'The General Rules Concerning University Organization and Procedure.'http://www.bot.uillinois.edu/general-rules
9Society of American Archivists.A Glossary of Archival and Records Terminology.http://www2.archivists.org/glossary/terms/p/provenance
10SPARC Europe. 'Publication embargo.'https://web.archive.org/web/20160226192027/http://sparceurope.org/embargoes/
11See Cloonan, Michèle and Martha Mahard.ILFA-ALIS-Euclid Conference August 8-9, 2010. Cooperation and Collaboration in Teaching and Research: Trends in LIS Education'Collaborative Approaches to Teaching Digital Stewardship: Classroom, Laboratory, and Internships.'http://conf.euclid-lis.eu/index.php/IFLA2010/IFLA2010/paper/view/4/3
Information for Developers
Databank is the Ruby on Rails web application component of Illinois Data Bank. Within the repository system at the University Library at Illinois, the web application integrates with the
When a depositor confirms an intention to publish, the web application requests a
For more information on development of the Illinois Data Bank, please see our
Accessibility
Research Data Service staff are committed to making the Illinois Data Bank service available to everyone. We are continuously improving the Illinois Data Bank for accessibility but understand that there may be areas and tasks that are not optimized for all access methods.
Research Data Service staff are happy to assist with the data deposit or access process if you encounter technical or navigation trouble. Do not hesitate to